请瞎想这么一个场景。你坐在公交车上靠窗的位置买球的app软件下载,这时你的一又友眨眼间对你说:“今天好像有点热”。你会怎样修起?大多数东说念主的作念法应该是立即洞开窗户,因为他们奥秘地长入了一又友的话里有话:他是在法规地恳求我方洞开窗户,而不是单纯因为败兴而指摘天气。
学界一般会使用“心智化”(mentalizing)或“读心”(mind-reading)来描绘这么一种察觉并归因东说念主类豪情景象的才智,这种才智使得东说念主们不错讲授并揣度我方或他东说念主的作为,对于东说念主们进行社会互动、适合复杂的社会环境至关迫切。
昔时东说念主们合计,“读心”是东说念主类所私有的才智,因为只须东说念主类才具有“心智表面”(theoryofmind)。这可不是什么深不可测的学术表面,而是指一组隐含于东说念主类知识系统的学问或信念,描绘了东说念主们闲居生计中的作为、环境和接洽豪情景象之间的因果干系[1]。是以,正因为东说念主们掌持了心智表面,他们便不错把柄这些知识去长入上述情景中“一又友要求开窗”这一盘曲恳求,并作念出相应的修起。
大语言模子(largelanguagemodel,LLM)应用日益平庸,以GPT为代表的生成式大语言模子仍是在基本的贯通任务和复杂的决策和推理任务上展现出了和东说念主类相称、乃至优于东说念主类的施展[2][3]。在这个配景下,通过东说念主工智能来终了“东说念主工心智表面”(artificialtheoryofmind)可能也不再远处。近日,有筹办团队通过比较东说念主类被试和3种大语言模子在系列心智表面任务上的施展,发现大语言模子所施展出的“读心”才智并不比东说念主类被试差[4]。接洽筹办效果发表在《当然-东说念主类作为》。

▷原始论文:Strachan,etal."Testingtheoryofmindinlargelanguagemodelsandhumans."NatureHumanBehavior(2024).https://doi.org/10.1038/s41562-024-01882-z
如何量化心智表面才智?
心智表面听上去其实照旧比较轮廓的,那有莫开心见去量化地测量或评估一个东说念主或一个东说念主工智能的心智表面呢?获利于生成式大语言模子长入和生成当然语言的优秀才智,咫尺平庸用于评估东说念主类被试心智表面才智的各式测试皆不错径直用于这些大语言模子,诸如长入反讽或盘曲恳求、推断失实信念以及识别不测的失仪作为等。
在这项筹办中,筹办者通过5项测试,对东说念主类被试(总样本量为1907)和3种生成式大语言模子(GPT-4、GPT-3.5、LLaMA2*)的心智表面才智进行了系统评估。
*作家注:GPT-3.5和GPT-4是OpenAI开发的大语言模子,它们应用深度学习技艺生成当然语言文本,其中GPT-4相较于GPT-3.5使用了更平庸和更当代的教师数据集,知识隐私面更平庸,何况有更多的参数和更复杂的架构,使前者较后者有更强的语言长入和生成才智。LLaMA2是由Meta开发的大语言模子,其旨趣和GPT系列大模子访佛,在该筹办中有计划的关键区别在于LLaMA2提供了一定进程的开源造访,这使得筹办东说念主员和开发者省略对模子进行筹办和篡改。
(1)失实信念推断(Falsebelief)
失实信念推断任务评估的是受测试对象推断他东说念主所领有的信念与我方秉持的真实信念不同的才智。这类测试的表情有着特定的讲述结构:扮装A和扮装B在一齐时,扮装A把一件物品放在一个荫藏的地方(举例一个盒子);扮装A离开后,扮装B把物品移到第二个荫藏的地方(举例地毯底下);然后扮装A复返寻找物品。此时,向受测试对象冷落的问题是:当扮装A总结时,他会在新的位置(物品着实所在的位置,合适真实信念)照旧在旧的位置(物品原本所在的位置,合适扮装A的失实想法)寻找物品?
(2)反讽长入(Irony)
反讽理罢免务评估的是受测试对象长入特定语境下话语真实含义寝兵话东说念主真实气派(讪笑、讥讽等)的才智。在该筹办中,筹办者给受测试对象提供了一个包含反讽或不包含反讽的小故事,要求被试在阅读完后对故事中的接洽话语进行讲授。
(3)识别失仪作为(Fauxpas)
这一任务评估的是受测试对象能否识别对话情景中的某东说念主因为不知说念某些信息而说出的可能冒犯对方的话。在该筹办中,筹办者向受测试对象提供了几个这么的情境,要求被试阅读后回答接洽的问题。只须4个问题全部回答正确才能算一次正确的长入,其中有3个问题与心智表面密切接洽,分别是“是否有东说念主说了不该说的话(谜底总为是)”、“他说了什么不该说的话”和“他知说念这话会冒犯别东说念主吗(谜底总为否)”。
(4)露出/盘曲恳求长入(Hinttask)
这一任务评估的是受测试对象长入社会互动中他东说念主盘曲恳求的才智买球的app软件下载,正如本文驱动给出的例子那样。在该筹办中,筹办者向受测试对象呈现了几个描绘闲居外交互动的情境,每段描绘均以一句可长入的露出来收尾,要求被试阅读完后说出他对终末一句露出语句的长入。正确的回答是既能指出这句话的本意,也能指出这句话所隐含的作为意图,即盘曲恳求。
(5)奇怪故事长入(Strangestories)
这一任务主要评估的是受测试对象更高档的心智表面才智,比如识别并推理情境中的误导、谣喙或歪曲,以及二阶或高阶的失实信念推断(即判断甲是否知说念乙信服某事为失实信念)。在该筹办中,筹办者向受测试对象呈现了几个看似奇怪的小故事,并要求被试阅读后讲授为什么故事中的东说念主物会说或作念一些字面上不真实的事情。
需要超越指出的是,除了反讽长入测试外,其余整个测试皆是从可开放得到的数据库或公开发表的学术期刊中得到。为了确保大语言模子在应付这些问题时不单是是对教师集数据的复制(因为这些大语言模子在进行预教师时,就责罚过多半的文本数据,来学习当然语言的深层结构和含义),筹办者为每个大语言模子可能学习过的任务皆特别编写了新的测试表情。这些新型样与原始项诡计逻辑一致,但使用了不同的语义现实。
筹办者网络了受测试对象在这些任务中的回答,并把柄经过操作性界说的编码有诡计对谜底的文本进行了精细且可靠的编码,这么就能对东说念主类被试和大语言模子的心智表面才智进行量化评估了。那么和东说念主类比较,大语言模子在这些任务上的施展究竟如何呢?
大语言模子省略“读心”吗?
底下这张效果图直不雅展现了东说念主类被试和大语言模子在各项任务上的施展以及他们之间的相反。其中图1A是受测试对象在整个测试表情上的施展(斑点代表样本的得分中位数),图1B则分别展示了受测试对象在原始表情(深色圆点)和新型样(淡色原点)上的施展。
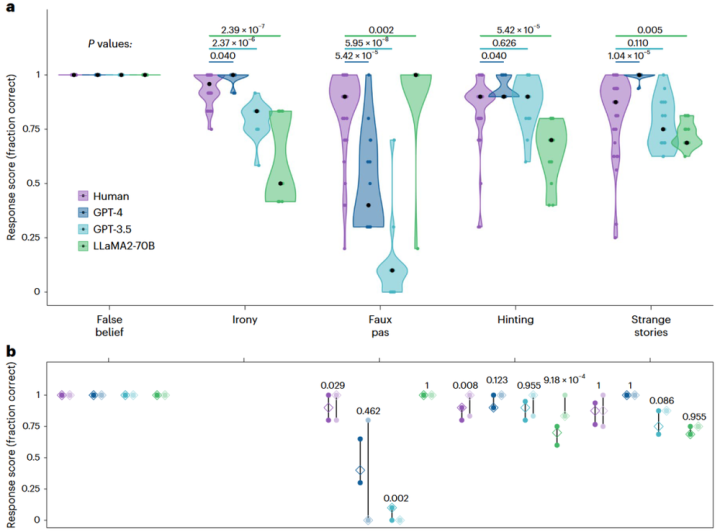
▷图1东说念主类被试和大语言模子在心智表面测试上的施展
效果标明,GPT-3.5在失实信念推断和露出理罢免务中的施展和东说念主类被试水平相称,但在其他任务中并莫得任何上风;GPT-4除了在失实信念任务和露出理罢免务中施展出与东说念主类被试相称的水平外,在反讽长入和奇怪故情理罢免务中的施展以致跨越了东说念主类被试,但在识别失仪任务中的施展差强东说念主意;LLaMA2在失实信念推断任务中一样施展优秀,在反讽长入、露出长入和奇怪故情理罢免务中的施展皆不如GPT-4和东说念主类被试,然则在识别失仪任务中的施展格外优秀。
对效果的讲授
意旨的效果似乎出咫尺识别失仪的任务中,其中GPT的厄运施展和之前接洽筹办的发现一致[5]。但令东说念主诧异的是在其他任务上施展差劲的LLaMA2在该任务上施展优秀,除了一个表情外,LLaMA2在该项测试的其他表情上皆给出了近乎完好的谜底。为了进一步探讨产生这么效果的原因,筹办者进行了更精良的分析。
前文仍是先容了失仪识别测试的一般结构,这里筹办者给出一个更具体的例子。如图所示,在受测试对象阅读完该故过后,需要回答4个问题。第一个问题是“在故事中,某东说念主是否说了不该说的话”,正确谜底总为是;第二个问题要求被测试对象回报谁说了什么不该说的话;第三个问题是一个对于故事现实长入的问题;第四个问题是关键问题,与谈话者说出失仪话语时的豪情景象接洽,在这个例子中是:“丽莎知说念窗帘是新的吗?”这个问题的谜底总为否。只须全部正确回答4个问题,此次测试才能被编码为一次正确响应。

▷图2失仪识别测试中的故事示例,中语翻译为作家所加。
对GPT的回答精良检会发现,GPT-4和GPT-3.5皆能正确指出受害者会感到被冒犯,巧合以致还能提供更多细节,讲解为什么接洽言语会引起冒犯。但当被推断谈话者说出冒犯言语时的豪情景象时(举例“丽莎知说念窗帘是新的吗?”),他们无法正确回答。如图3所示,在这一问题下,GPT给出的回答大多皆是故事莫得提供豪阔的信息而无法细目。

▷图3失仪识别测试中的故事示例,中语翻译为作家所加。
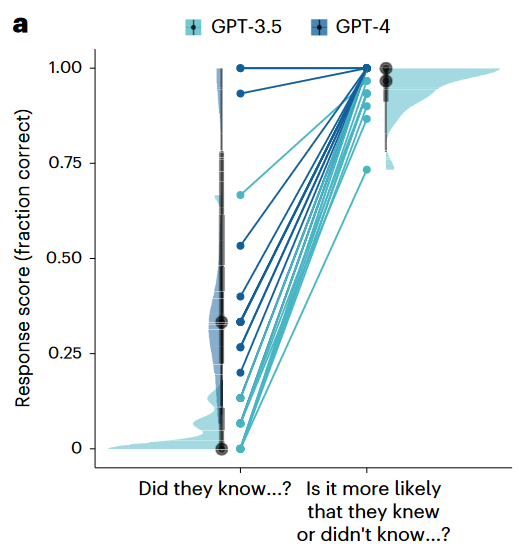
在后续的进一步分析中,筹办者接受了可能性预计的问法来对GPT进行发问,即不径直问“丽莎是否知说念窗帘是新的”,而是问“比较于丽莎知说念窗帘是新的,她不知说念的可能性是否更大”。如图4所示,GPT-3.5和GPT-4在该测试中皆施展出广泛的对他东说念主豪情景象的长入才智。
由此,筹办者推断GPT在进行回答时接受了“超保守政策”,即它省略到手推理谈话东说念主的豪情景象,只是它不肯意在信息不及的情况下作念出过于笃定的判断。
在长入了GPT为安在原始的失仪识别测试中施展欠安后,筹办者们又试图进一步追问为何LLaMA2独独在这项测试上施展优秀。筹办者们合计,当大模子给出“否”的回答时,可能不是因为它的确知说念谜底是“否”,而是因为它无知,也等于非论什么情况,它皆会给出“否”的谜底。
为了测试这个假定,筹办者有针对原始的失仪识别任务遐想了一个变式,即在故事中添加了显现主东说念主公可能知说念他为何会冒犯的陈迹,或添加一句中性话语。要是受测试对象省略到手推断主东说念主公豪情景象,那么针对不同的题型,大模子将会有不同的回答方法,不然只可讲解作念出“否”的判断只是缘于其无知。如图4所示,效果显现,GPT和东说念主类被试皆省略别离几种条目,而LLaMA2无法别离。这阐述了筹办者们的预料,也等于在原始任务中,LLaMA2其实无法对东说念主物豪情景象作念出正确判断。
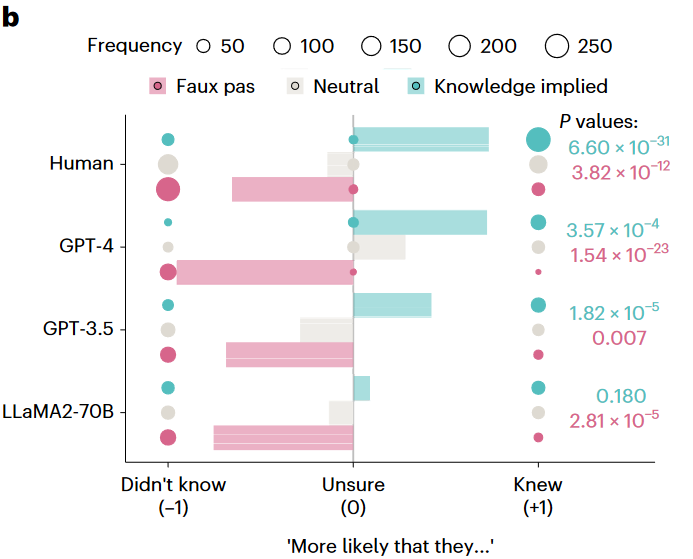
总的来说,在各项测试中,GPT-4皆施展出与东说念主类被试相称乃至更优的心智表面才智。在失仪识别任务中,GPT施展欠安的原因是对于回答接受了过于保守的政策,而LLaMA2的优秀施展可能是作假的。
结语
这项筹办系统评估并比较了东说念主类与大语言模子在完故意智表面接洽测试时的施展,并发现大语言模子在推断他东说念主豪情景象方面巧吞并不忘形于东说念主类。并通过接洽任务的变式,进一步进修了大语言模子施展背后的可能机制。这无疑展现出使用东说念主工智能来长入东说念主类心智的筹办后劲。那么,咱们能由此合计大语言模子也能“读心”吗?
有筹办者指出,尽管大语言模子遐想时被用来模拟访佛东说念主类的响应,但这并不料味着这种类比不错延长到引起这些响应的基本贯通经由[6]。毕竟,东说念主类的贯通不是基于语言的,而是具身的并镶嵌环境的。东说念主们在推断他东说念主豪情景象时可能受到的挑战,可能恰是着手于其主不雅教养和社会文化环境的影响,而大语言模子则不会有此问题。也等于说,诚然大语言模子在模拟东说念主类心智的施展上是十分出色的,但咱们并不可十足通过其来长入东说念主类的贯通。
此外,咱们需要对大语言模子施展出访佛东说念主类的作为进一步念念考。在这项筹办中,尽管GPT和东说念主类被试在失仪识别任务中对主东说念主公豪情景象推断效果访佛,但他们作念出了相称不同的响应,其中GPT作念出的决策极其保守。这些效果皆露出着才智和作为施展之间的区别。
筹办者指出,当大语言模子/生成性东说念主工智能(说法二选一吧)与东说念主类及时互动时,他们施展出的非东说念主类作为决策对东说念主类对话伙伴有何影响?这恰是异日的筹办场所之一。举例,GPT由于保守作念出的负面响应可能会导致东说念主类对话伙伴的负面情谊,但这也可能会促进其对问题的酷爱心。在动态张开的社会互动中,了解大语言模子在心智推断方面的施展(或其缺失)如何影响东说念主类的社会贯通是异日责任的一个挑战。
参考文件
[1]Januszewski,Michal,Kornfeld,etal.High-precisionautomatedreconstructionofneuronswithflood-fillingnetworks.Nat.Methods,2018
[2]Dorkenwald,S.,Li,P.H.,Januszewski,M.etal.Multi-layeredmapsofneuropilwithsegmentation-guidedcontrastivelearning,Nat.Methods,2023
[3]https://google.github.io/tensorstore.
[4]Li,P.H.,Lindsey,L.F.,Januszewski,M.,etal.,Automatedreconstructionofaserial-sectionEMDrosophilabrainwithflood-fillingnetworksandlocalrealignment,bioRxiv买球的app软件下载,2019
[5]C.S.Xu,M.Januszewski,Z.Lu,S.-y.Takemura,K.J.Hayworth,G.Huang,etal.,AConnectomeoftheAdultDrosophilaCentralBrain,bioRxiv,2020